INTELLIGENT TRAFFIC MANAGEMENT USING BIG DATA ANALYTICS AND IOT
ABSTRACT
With the fast increase of personal luxury and employment opportunities, people are more comfortable driving their own automobiles than using public transit to meet their mobility demands. This is due to the simplicity of access and the ability to utilize the cars at any time. This results in severe traffic congestion and lengthy wait times at traffic lights, which has become a significant hardship in all large cities. This will influence the environment due to the pollution generated by the large number of automobiles and will also disrupt the individual’s schedule. The purpose of this article is to demonstrate how data analytics, machine learning algorithms, and the Internet of things may be used to forecast traffic flow, create exact data regarding real-time traffic congestions, and reroute cars utilizing navigation to a less crowded course. The system’s design is based on image analysis of cars utilizing cameras at traffic signals, as well as the use of GPS in mobile devices to monitor traffic along a certain route. When these two factors are combined, meaningful statistics concerning traffic congestion may be generated. The next section calculates the most efficient route to the destination using the provided data in order to reduce traffic and arrive in a short amount of time.
I. INTRODUCTION
The primary contributor to the issue of “Traffic Congestion” is the usage of private automobiles for commuting rather than public transportation. There may be a variety of personal reasons why individuals are unable to take public transportation. However, this issue cannot be resolved just by encouraging individuals to utilise public transportation rather than their own automobiles. We devised an intelligent solution to this issue using new developments in machine learning and several algorithms for data analysis. With the fast advancement of communication and sensing technologies, low-cost and effective sensors, greater data storage and retrieval efficiency, and low-cost storage of large amounts of data, it is simple to extract and utilise data for our convenience. The present traffic control system employs a pre-programmed time interval mechanism for signal changes. The primary problem in Data Analytics is gathering relevant and useable data in order to design a solution. Continuously updated data must be uploaded to the data model, and the prediction techniques generated by algorithms must be capable of delivering correct reports from this ever-growing data.
The primary data source for this project is crowdsourced data. Nowadays, with the advancement of technology in the vehicle sector, a GPS sensor is being employed for automotive smart applications. GPS data collected from autos may be quite beneficial in developing the data model. The GPS sensor (global positioning system) determines the vehicle’s precise location. With the position of all autos, it is possible to anticipate whether or not there is traffic congestion. This data is especially valuable for determining the traffic rate or density of traffic at a certain place. The traffic density may be estimated by comparing the position of a given car to the number of cars present within a 100-meter radius of that place. The vehicle’s speed also has a significant impact in this. Another source of helpful data is the CCTV cameras installed on the route.
Image analysis techniques may be used to estimate the number of automobiles on the route. OpenCV is a collection of computer vision-related functions geared primarily at real-time computer vision. This can be used for real time video analysis to calculate number of vehicles that are being crossed. Eventually we can calculate traffic rate using the time for a vehicle to cross the CCTV. We can also calculate traffic density by counting number of vehicles present on the road compared with the speed of the vehicle.
One of the great components of the proposed architecture has been reified in a platform prototype which relies specifically on a Kafka, an effective tool for efficient processing of Big Data streams. Thanks to the built-in mechanisms of Kafka, the records evaluation is scalable, i.e. can scale to a big number of records sources concurrently sending records at excessive rates, and reliable, i.e. it can tolerate hardware faults without loss of records.
The remaining of the paper is structured as follows: In Section II, we present an overview of existing traffic control mechanisms and Intelligent approaches using various technologies. In section III, detailed explanation of proposed architecture and how it can overcome present approaches for intelligent traffic management. In section IV, we discuss the conclusions and expected results with our recommendations to further research.
II. BACKGROUND
Characteristics of Intelligent Traffic management System:
The goal of this work is to use Kafka, one of the most popular Big Data techniques, to develop an extendable real-time traffic management system. As a result, it’s critical to investigate the similarities and differences between the present control system and Kafka stream analytics. The observation of the situation (data collection) and the execution of the determined control strategy are the two basic components of real-time traffic control systems (data processing and information dissemination). A local system examines real-time input data, which is then combined and processed to determine the scenario (e.g., incident detection). When a threshold is exceeded, the controller objective function is optimized using one of the established techniques. In certain instances, a central system sets the strategic goal, while local systems are flexible enough to behave adaptively in response to changing circumstances. The most prevalent traffic control techniques are the feedback loop and model predictive control (MPC). They are, however, mostly single-objective and need data that has been purposefully perceived (i.e., fundamental traffic flow parameters).
Big Data Analytics
By using a collection of storage and processing units dubbed clusters, Big Data analytics techniques scale in terms of the volume and speed of data that has to be examined. This overcomes the limitations of a single CPU and hard drive capacity but adds complexity to the process of configuring and running the relevant tools. The core premise of Big Data analytics is “bringing computation to data”: each computer in a Big Data cluster acts on its own set of locally stored data (map function); the results from individual machines are then aggregated and summarized (reduce function). Different Big Data analytics solutions have evolved to support a variety of applications and user demands. The primary contrast is between tools that do what are known as batch analytics on historical data, which is often stored in a Hadoop Distributed File System (HDFS) or a NoSQL database (e.g., Cassandra, HBase). Spark, Hadoop’s MapReduce, and Tez, as well as various SQL-like front ends such as Hive and Pig, are all examples of batch analytics technologies. On the other hand, there are tools that use stream analytics, that is, those that analyses data as it arrives in preset time frames. This is ideal when data-driven choices must be made quickly. Flink, Kafka Streams (a Kafka extension), and Spark Streaming are all noteworthy technologies in this area.
III. BIG DATA ANALYTICS METHODS
Machine learning is the most widely used modelling and analytics technique in Big Data ecosystems, since it enables the extraction of patterns and models from massive amounts of data. Machine learning theory has also been extensively used in ITS sectors to undertake data analytics. Machine learning algorithms may be classified as supervised, unsupervised, and reinforcement learning methods, depending on the completeness of the data set available for learning. With the fast growth of Artificial Intelligence in recent years, strong deep learning models have been used to ITS.
Supervised Learning
Supervised learning is a subset of machine learning in which computers are trained on well-labeled training data and then predict the output based on that data. Labeled data indicates that some input data has already been marked with the desired output. In supervised learning, the training data presented to the machines acts as a supervisor, instructing the machines on how to accurately anticipate the output. It employs the same principle that a student learns under the teacher’s supervision. Supervised learning is the process of giving the machine learning model with both proper input and output data. A supervised learning algorithm’s objective is to discover a mapping function that maps the input variable (x) to the output variable (y).
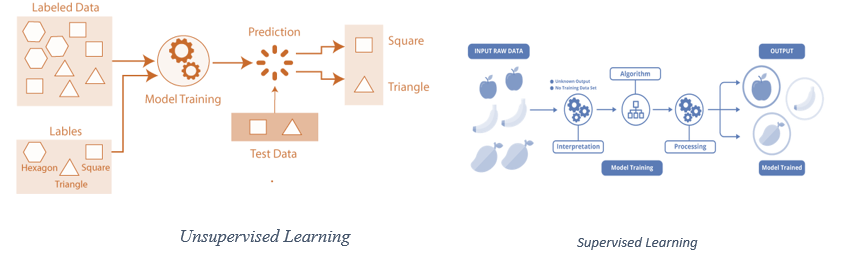
Unsupervised Learning
In certain pattern recognition tasks, the training data consists of a collection of input vectors x that do not have any associated target values. The objective of such unsupervised learning tasks may be to locate clusters of similar instances within the data, a process known as clustering, or to calculate the distribution of the data in space, a process known as density estimation. To put it another way, with an n-sampled space x1 to xn, no genuine class labels are supplied for each sample, resulting in what is referred to as learning without a teacher.
Unsupervised Learning Issues:
· Unsupervised Learning activities are more difficult than Supervised Learning activities.
· How can we know whether the findings are meaningful in the absence of response labels?
· Allow a professional to examine the findings (external evaluation)
· Define a clustering objective function (internal evaluation)
Unsupervised Learning can be further classified into two categories:
Parametric Unsupervised Learning
In this situation, we suppose that the data are distributed parametrically. It is predicated on the assumption that sample data originate from a population with a probability distribution defined by a predefined set of parameters. In theory, every member of a normal family of distributions has the same form and is parameterized by the mean and standard deviation. That is, if you know the mean and standard deviation of the distribution and assume that it is normal, you can calculate the probability of any future observation. It involves the building of Gaussian Mixture Models and the use of the Expectation-Maximization method to forecast the sample’s class. This instance is far more difficult than conventional supervised learning since there are no response labels and hence no proper measure of correctness to validate the outcome.
Non-parametric Unsupervised Learning
In the non-parameterized version of unsupervised learning, data is clustered, and each cluster (ideally) contains information about the categories and classes represented in the data. This is a frequently used technique for modelling and analysing data with tiny sample sizes. In contrast to parametric models, nonparametric models do not need the modeller to make any assumptions about the population’s distribution and are hence sometimes referred to as a distribution-free technique.
Deep Learning
Deep learning models can achieve better performance than traditional machine learning models. They have been widely applied in Intelligent Traffic Management systems. In traffic flow area, deep learning model has become a popular tool to predict traffic flow density. Deep learning models make use of a broader range of system features and a more complicated design than typical Artificial Neural Networks, and so can outperform typical machine learning models. They have been extensively implemented in ITS systems. For example, using GPS data from taxis, a deep Restricted Boltzmann Machine and Recurrent Neural Network architecture is used to simulate and forecast the growth of traffic congestion. With the use of Big Data, defect diagnosis on bogies is carried out using deep neural networks. The input is made up of data received from all highways. Taking into account the temporal relationship of traffic flow, data from previous time intervals, i.e, χt−1,χt−2,…,χt−l, are utilised to forecast traffic flow at time interval t. The proposed model intrinsically takes into consideration the geographical and temporal correlations of traffic flow.
Kafka
Event streaming is the virtual equal of the human body’s critical worried system. It is the technological basis for the ‘always-on’ international wherein agencies are an increasing number of software program-defined and automated, and wherein the consumer of software program is extra software program.
Technically speaking, occasion streaming is the exercise of shooting statistics in real-time from occasion sources like databases, sensors, cellular devices, cloud services, and software program programs withinside the shape of streams of events; storing those occasion streams durably for later retrieval; manipulating, processing, and reacting to the occasion streams in real-time in addition to retrospectively; and routing the occasion streams to different vacation spot technology as needed. Event streaming therefore guarantees a non-stop float and interpretation of statistics in order that the proper facts is on the proper place, on the proper time.
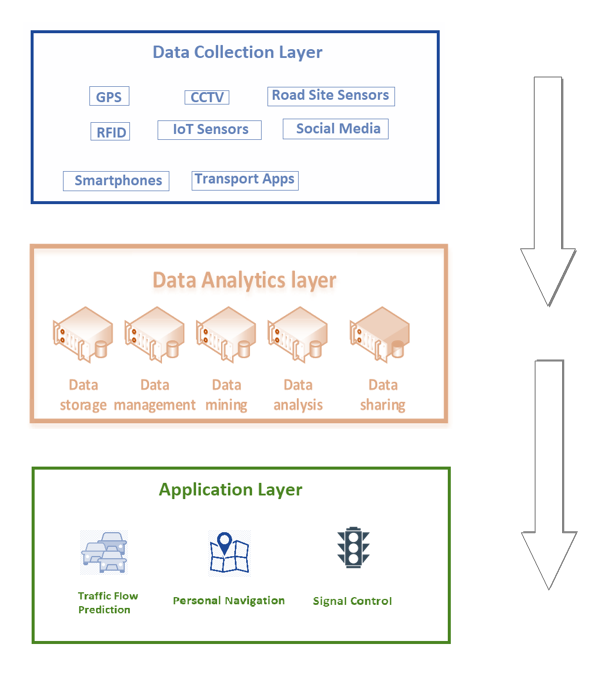
IV. BIG DATA COLLECTION SOURCES:
Big Data From GPS
GPS is the most widely used method of tracking one’s whereabouts. With GPS position monitoring, traffic data may be obtained more effectively and securely. By combining geographic information systems (GIS) or other map-display technologies, GPS offers a potential tool for data collecting, and the acquired data may be utilised to solve a variety of traffic challenges, including travel mode recognition, trip delay assessment, and traffic monitoring.
CCTV Image processing
Many communities now have affordable video surveillance systems, commonly called closed-circuit television (CCTV). They have seen remarkable expansion in recent years and often comprise a variety of cameras with varying resolutions, mounting points, and frame rates. CCTV operates 24 hours a day, seven days a week, and creates vast amounts of data, dubbed Big Data. Among other things, this data may be used to provide the groundwork for an automated traffic monitoring system.
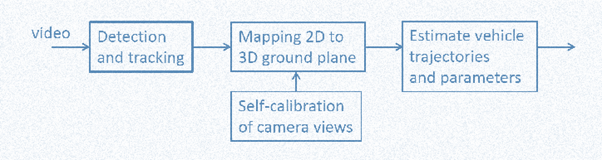
This system consists mainly of two blocks:
· Object detection
· Multi Object tracking
Object Detection
As of now, the majority of object detectors are based on convolutional neural networks (CNN) and fall into one of two categories: single-stage detectors and two-stage detectors. Single-stage detectors are often quick and can predict the bounding boxes of objects as well as classes in a single network run. YOLO [5] and SSD [4] are two well-known single-stage detectors. These designs perform especially well when the target items take up a significant portion of the picture. The famous UA-DETRAC vehicle detection dataset is an example of this kind of data [7]. Dmitriy Anisimov and Tatiana Khanova [1] demonstrated with this data that a properly developed SSD-like detector can operate at speeds more than 40 frames per second on a current CPU while retaining acceptable accuracy. Another example of a good speed-precision trade-off is the YOLO v2 architecture [30], which was optimised for vehicle recognition via the use of anchoring clustering, extra loss normalisation, and a multi-layer feature fusion method.
Multi-object tracking
Due to the advancements in the accuracy of the object detectors stated before, the tracking-by-detection paradigm has become the de facto standard for multi-object tracking (MOT) tasks. Tracking is defined as a data association (DA) issue in this paradigm, with the goal of combining fuzzy detections over numerous frames into extended tracklets. Traditionally, tracking-by-detection approaches depend only on motion information from the detector and address the DA issue using optimization approaches. Multiple Hypothesis Tracking (MHT) [3] and Joint Probalistic Data Association Filter (JPDAF) [6] are well-known examples. Although these algorithms address the association issue frame by frame, their combinatorial complexity grows exponentially with the number of monitored objects, rendering them unsuitable for real-time tracking. On the other hand, a recent SORT tracker [2] shown that a basic Hungarian algorithm with Kalman filtering for movement predictions may attain real-time processing speed while preserving acceptable performance.
Big Data from Sensors
Sensors deployed in ITS capture data such as vehicle speeds, vehicle density, traffic flows, and travel times. On-road sensors (e.g., infrared and microwave detectors) have evolved to collect, calculate, and transmit traffic data [8]. As described in [8], sensor data gathering may be classified into three categories: roadside data, floating automobile data, and broad area data [9]. The term “roadway data” refers mostly to data gathered by sensors situated along the roadside. For many years, conventional roadside sensors such as inductive magnetic loops, pneumatic road tubes, piezoelectric loop arrays, and microwave radars were employed. With recent advancements in technology, next generation roadside sensors including as ultrasonic and acoustic sensor systems, magnetic vehicle detectors, infrared systems, light detection and ranging (LIDAR), and video image processing and detection systems are progressively becoming available. Floating car data (FCD) primarily refers to vehicle mobility data collected at various places within an ITS system using specific detectors implanted in cars [10]. Certain onboard sensors give reliable and efficient data for route selection and estimate. Popular FCD sensor technologies include automated vehicle identification (AVI), licence plate recognition (LPR), and transponders such as probing cars and electronic toll tags. Wide area data refers to traffic flow data acquired over a large area using a variety of sensor monitoring methods, including photogrammetric processing, sound recording, video processing, and space-based radar.
Sensors are being introduced in the car sector at the moment to monitor each and every aspect of the vehicle. The route is evaluated, and things are detected using 3D Mapper. This is used to identify obstacles in self-driving automobiles. The technique is used with machine learning to enhance item recognition and classification based on their form and motion. This data from the car may be communicated through IoT, which may be quite beneficial in terms of supplying big data for the analytics of intelligent traffic management system.
Social Media
Social Media (alternatively referred to as Social Networking Services or Social Networking Sites) is a Web 2.0 product that has turned the Internet from a domain of information to one of interaction and influence.
The fundamental meaning of social media is fascinating, owing to the breadth of services available.
We may summarise it as follows: “Social Media are web-based apps that enable users to interact with one another.”
For consistency’s sake, we will utilise Boyd and Ellison’s definition of social media, which defines it as services that enable users to: a) maintain a public or semi-public personal profile; b) build a social network by connecting to other users; and c) explore and respond to connections.
In contrast,
With a study environment in mind, Kietzmann et al. developed a honeycomb structure comprised of seven distinct social media functionalities:
a) presence
b) sharing
c) conversations
d) groups
e) reputation
f) identity
g) connections with each Social Media site to strive for a mixture of the above, with a preference for three or four features.
Open-Source Data From Cab Services
With the increase in use of cab services like Uber and Lyft by the customers, this data of automobiles and traffic routes that are being used by the application can be used to feed the data model and predict traffic which can provide better results while predicting the traffic. The data from such apps can be reliable and can be accurate as the drivers follow the path that is being shown in the app and the data will be updated from time to time. From this we can obtain real time changing data in the city or the real time updates in the traffic. This data can also be used to train models as some of the data will be recurring daily as some may be preferring to travel via cabs daily for their work.
V. ARCHITECTURE
Travel speed prediction has been one of the most difficult issues to address. Individual data sources, such as CCTV cameras and traffic sensor data, have traditionally been used by controllers to feed regression or time-series forecasting models. These methods don’t take use of the vast amount and diversity of transportation data that can be analyzed using contemporary data, engineering, and machine learning tools. cutting-edge deep learning can be utilized to create speedy, high-performance speed forecasts for the road network under typical operating circumstances by ingesting and integrating enormous volumes of diverse data. When the road network is not running normally, the most intriguing situations to investigate are often present. If there is a special event, construction on the road, or a traffic incident. Due to a paucity of training data, AI models have traditionally struggled with occasional non-recurring occurrences like these. Several methods for generating high-quality forecasts in certain circumstances, including using classic traffic simulation to analyze crucial non-recurrent occurrences can be implemented. The simulation may run many scenarios and compare the results for travelers using pre-configured reaction strategies.
The data analytics engine analyses and/or controls the logic established by each customer, which might range from a basic feedback loop to complex machine-learning algorithms. Additionally, customers may select the time intervals for getting the analytics engine’s output. As data is received, it is handled using user-defined reducer functions. These functions are topic specific. For instance, in the case of speed data, a suitable reducer function may calculate the incoming data’s moving average. A separate evaluator function is run at the conclusion of each time period. The evaluator has access to the outputs of all reducers; here is where judgments may be made based on the combined analysis of the various reducers. In the case of automated traffic control, the evaluator activates modifications to the traffic system on a conditional basis through the change provider.
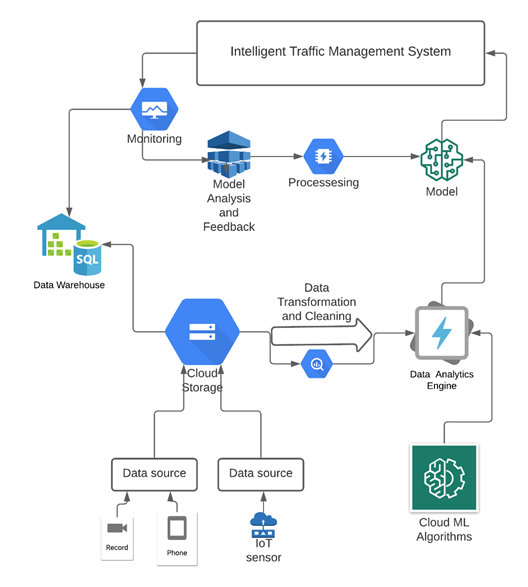
Deep learning algorithm is implemented in the prediction model based on the algorithm described in . Essien [11] . The proposed framework is composed of an eight-layer bidirectional LSTM stacked autoencoder. The Rectified Linear Unit (ReLU) was employed as the activation function for all interconnected layers (excluding the output layer), which injected non-linearity into the learning process. Deep learning network performance is highly reliant on important parameters that must be established via a process called hyperparameter optimization or hyper-parameterization. To determine the ideal set of hyperparameters for this investigation, we used a grid search methodology.
The algorithm consists of the following steps to evaluate:
Input: Gathered sequence of data of a particular area
Outupt: Predicted traffic flow of a particular road of the area
· Divide the real-world data obtained into 70:30 ratios for training and testing.
· Select a look back step size of b in the training data, and at time t, create lookback observations as x1,x2,x3,…
· xb as the input and xb+1 as the expected value yt
· Establish a random initialization procedure for model parameters, weight wt and bias c.
· Train the model using a forward greedy-layer wise approach and update the model parameters using bi-directional processing.
· The back propagation algorithm optimizer is used to update the model.
· Loss function minimization
· Utilize test data for model validation and another batch of training data for a subsequent retraining procedure.
· Rep until the training set is completed.
· Return the output sequence of the prediction Y.
VI. CHALLENGES
Data privacy
The most perplexing and concerning issue in the age of Big Data is privacy. Personal information may be compromised during data transfer, storage, and use. Historically, data acquired from transportation networks were non-personal in nature, such as car location and traffic flow data. However, privacy concerns have grown as personal data collecting by the public and commercial sectors increases over time. For instance, the position of persons and vehicles may readily be gathered. If this data is not securely safeguarded, those who steal them will do damage to the data owner. As a result, privacy protection is critical for Big Data applications in ITS. To avoid unlawful exposure of personal private information, governments should adopt comprehensive data privacy rules that cover what data may be released, the breadth of data publication and use, the fundamental principles of data distribution, and data accessibility, among other things. Transportation agencies should tightly restrict the definition of personal data, tighten their administration of data security certification, and use more complex algorithms to increase the level of data security.
Processing power
For Big Data applications in Intelligent Traffic management system, timeliness is critical; these applications include traffic data pre-processing, traffic state recognition, real-time traffic control, dynamic route guiding, and real-time bus scheduling. Traffic data in a variety of forms from a variety of sources must be compared to historical data and then processed quickly. The data processing system must be capable of handling more complex and growing data. How to ensure process timeliness with so massive and quick data is a significant concern. Numerous general-purpose Big Data frameworks that support real-time data sources have emerged lately, including Apache Storm, Apache Flink, Apache Samza, Apache Spark Streaming, and Kafka Streams. Additionally, special Big Data processing frameworks for ITS have been created, including a platform for real-time traffic management and predicting the average speed and congested areas of a route. These frameworks offer effective solutions for real-time data processing. To deploy these services in cloud platform for real time monitoring and feedback requires a lot of processing power, storage, and stable internet connection to transfer bulk data files across different platforms for storage and processing.
Power usage
A continuous monitoring system must be created to always collect data. This can ensure that the forecast is correct and that the model is updated on any accidents or occurrences that may affect the model’s assessment. High power is used to keep the systems operational 24 hours a day, seven days a week.
VII. CONCLUSION
We presented a complete and adaptable architecture for real-time traffic management based on Big Data analytics with deep learning in this paper. The architecture is the result of a methodical examination of the domain’s needs. Real time deep learning algorithms simultaneously combined with kafka streaming or spark streaming services for the data flow can lead to development of highly optmised model for prediction of the traffic. The study’s primary weakness was a lack of access to real-world data. By training the model using real-world data, we can significantly increase the model’s efficiency. Data collection is a significant constraint. Maintaining such massive volumes of data requires a great deal of work and management mechanisms.
Despite its simplicity, this real-world example necessitates the analysis of vast and diverse data streams from various sources. While using such a platform to perform only traditional control measures requires considerable effort, such multi-objective control platforms are critical for emerging autonomous vehicles, particularly for coordinating control measures among all components simultaneously, such as strategic decisions for individual vehicle movement. With the advancement of autonomous vehicle technology, the model may be very beneficial in assisting a car in predicting traffic flow and redirecting to another route. Thus, more research may be conducted to combine this technology with driverless autos and other vehicles in order to intelligently route users to their destinations with minimal traffic interruptions. Another area to investigate is the use of IoT in the construction of smart cities, which may significantly aid in the collection of real-world data for the model.
